In diesem ersten „richtigen“ Kapitel des XML Tutorials werden die Grundlagen rund um die XML-Sprache gelegt. Man erfährt hier mehr über die zentralen Bestandteile: Elemente und Attribute. Neben einigen grundlegenden Erklärungen findet man hier auch viele praktische Beispiele, die die Theorie veranschaulichen sollen. So erfährt man nicht nur was ein Element bzw. Attribut ist, sondern wie dieses auch unterschiedliche eingesetzt werden kann. Am Ende des Kapitel erfährt man darüber hinaus noch etwas über den allgemeinen Aufbau von XML-Dokumenten anhand eines XML-Baums.
Inhalt
Hier geht’s um XML!
Bevor wir zum Aufbau von XML kommen, in dem näher auf die beiden Bestandteile: Elemente und Attribute eingegangen wird, muss an dieser Stelle noch auf die nachfolgende Zeile hingewiesen werden, die in keinem XML-Dokument fehlen darf!
<?xml version="1.0"?>
Hier handelt es sich um den sogenannten XML Prolog der besagt, dass es sich hier um XML nach der Version 1.0 handelt. In der oberen Form ist der Prolog minimal. Man kann zusätzlich noch die Attribute „encoding“ und „standalone“. Während man mit „encoding“ einen Zeichensatz für das Dokument bestimmen kann (Standard ist UTF-8) kann man mit „standalone“ mitteilen, ob es Deklarationen gibt, die außerhalb des Dokumentes stehen. Wie gesagt sind diese beiden Attribute optional und sollen an dieser Stelle erst einmal keine weitere Rolle spielen. Im Regelfall wird aber noch das encoding mit angegeben, sodass man am Anfang vieler XML-Dokumente den folgenden XML Prolog vorfindet:
<?xml version="1.0" encoding="utf-8"?>
Aufbau von XML
Wer sich schon in HTML ein bisschen auskennt, der dürfte sich auch in XML schnell zurecht finden, da beide Auszeichnungssprachen auf SGML basieren und so große Ähnlichkeiten in ihrem Aufbau aufweisen. Wie auch bei HTML stehen auch bei XML die sogenannten Tags im Mittelpunkt, die durch zwei spitze Klammern umschlossen werden. Neben einem öffnendem Tag muss/sollte es auch immer ein dazugehöriger schließender Tag im Dokument auftauchen (das ist unter anderem eine Bedingung für die Wohlgeformtheit eines XML-Dokuments, dazu aber gleich mehr). Ein öffnender und ein schließender Tag, sowie die darin enthaltene Ausschnitte nennt man Element. Dementsprechend ist der Elementname der Name des Tags:
<tagname>INHALT</tagname>
Ein Element kann verschiedene Inhalte aufweisen und ist Träger der Information in einem XML-Dokument. Dieser Inhalt kann ein einfacher Text sein, weitere Elemente oder aber auch eine Mischung aus beidem. Dadurch kann ein verschachtelter Aufbau des Dokuments erfolgen:
<tutorial> <lektion>Aufbau von XML</lektion> <lektion>Folgt bald …</lektion> </tutorial>
Wie man sieht, taucht hier das ELement „lektion“ gleich zwei Mal innerhalb des Elements „tutorial“ auf. Dies ist eine wichtige Eigenschaft, wie man später, insbesondere beim Vergleich mit Attributen, sehen wird.
Elemente können Attribute zugewiesen werden. Diese fügt man einfach in den jeweiligen Start-Tag ein:
<tutorial schwierigkeitsgrad="einfach"></tutorial>
Ist das Element übrigens leer, dann kann man in diesem Fall auf das schließende Tag verzichten und stattdessen das öffnende Tag mit ein / wieder schließen.
<tutorial schwierigkeitsgrad="einfach"></tutorial>
Kann also auch folgendermaßen geschrieben werden:
<tutorial schwierigkeitsgrad="einfach" />
An dieser Stelle kann man sich nun die Frage stellen, ob man eine Information in einem XML-Dokument als Element oder doch als Attribut darstellen möchte. Beispielsweise habe ich die Information „XML Tutorial“. Nun kann ich diese entweder als Element:
<tutorial>XML</tutorial>
oder aber auch als Attribut:
<tutorial bezeichnung="XML"></tutorial>
darstellen. Für ein Element spricht, dass ein Element aus weiteren Elementen bestehen und man generell Elemente wiederverwenden kann. Dafür ist die Reihenfolge, in denen die Elemente auftreten können, relevant (siehe dazu auch später das Kapitel Datenmodelle). Ein Attribut ist hingegen für elementare, nicht weiter zerlegbare Informationen geeignet, über das man zu dem noch Meta-Informationen zum Inhalt weitergeben kann. Attribute können nicht alleine auftreten, sondern sind immer Bestandteil eines Elements. In solch einem Element kann ein Attribut bzw. dessen Namen nur einmal auftauchen, es wäre also nicht möglich dem oberen Element „tutorial“ die Attribute „bezeichnung=XML“ und „bezeichnung=Java“ mitzugeben.
Generell führen also viele Wege nach Rom und es gibt bei der Konzeption eines XML-Dokuments kein „richtig“ oder „falsch“.
Folgende Faustregel kann (muss man aber nicht!) man allerdings anwenden:
- handelt es sich um informationstragende Nutzdaten –> Element
- handelt es sich um Metadaten –> Attribut
Wem diese Faustregel nicht reicht und sich etwas intensiver mit dem Thema „Element vs. Attribut“ beschäftigen möchte, dem sei folgender englischer Artikel ans Herz gelegt: http://www.ibm.com/developerworks/xml/library/x-eleatt/index.html
Wohlgeformtheit
Um Wildwuchs zu vermeidet, hat man die sogenannte Wohlgeformtheit eingeführt. Im Grunde versteht man unter einem wohlgeformten Dokument (engl. well-formed document) einfach ein Dokument, das die in XML 1.0 spezifizierten Syntax-Regeln einhält. So muss für eine wohlgeformte Elementstruktur gelten:
- Alle Elemente (außer leere Elemente) die ein Start-Tag besitzen, müssen auch ein End-Tag besitzen
- Wenn es mehrere Elemente gibt, z.B. <a> und <b> und <a> vor <b> im Dokument steht, dann muss auch </b> vor </a> kommen. Man kann sich das wie eine Zwiebel vorstellen, bei der die äußerste Schicht die innere Schicht komplett umschließt und diese sich nicht überkreuzen. Wohlgeformtheit würde bei <a><b></a></b> beispielsweise nicht vorliegen, sondern entweder bei <a></a><b></b> oder verschachtelt bei <a><b></b></a>
- Das Dokument besitzt ein Wurzelelement (Dokumentenelement), also genau ein Element, das in keinem anderem enthalten ist. Es handelt sich dabei um das äußerste Element und zieht man die Analogie der Zwiebel noch einmal ran, könnte man damit die Zwiebelschale bezeichnen
Im Gegensatz zu HTML, wo die Browser Unstimmigkeiten sehr wohlwollend handhaben, müssen XML-Dokumente diese Wohlgeformtheitsregeln prinzipiell strikt einhalten. Man findet im Internet einige XML-Validator, mit denen man unter anderem die Wohlgeformtheit eines Dokuments überprüfen kann. Ich empfehle hierfür folgende Seiten:
- http://www.xmlvalidation.com/?L=2
- http://www.freeformatter.com/xml-validator-xsd.html
- http://www.utilities-online.info/xsdvalidation/
XML-Baum
Durch die Möglichkeit des verschachtelten Aufbaus eines Dokuments kann das Dokument durch diese „Hierarchie“ auch als Baum dargestellt werden. Das oberste Element des XML-Baums ist dabei immer das Wurzelelement. Von diesem gehen anschließend die verschiedenen Zweige ab, die selbst wiederum ebenfalls verästelt sein können.
Nachfolgend ein etwas größeres XML-Dokument gefolgt von seiner Baum-Repräsentation:
<?xml version="1.0" encoding="UTF-8"?> <tutorials> <javascripttut> <schwierigkeit>Mittel</schwierigkeit> <lektionen> <lektion dauer="15" nr="1">Einstieg</lektion> <lektion dauer="30" nr="2">Schleifen</lektion> <lektion dauer="30" nr="3">Bedingungen</lektion> </lektionen> </javascripttut> <xmltut> <schwierigkeit>Leicht</schwierigkeit> <lektionen> <lektion nr="1">Aufbau</lektion> <lektion nr="2">Vieles mehr</lektion> </lektionen> </xmltut> </tutorials>
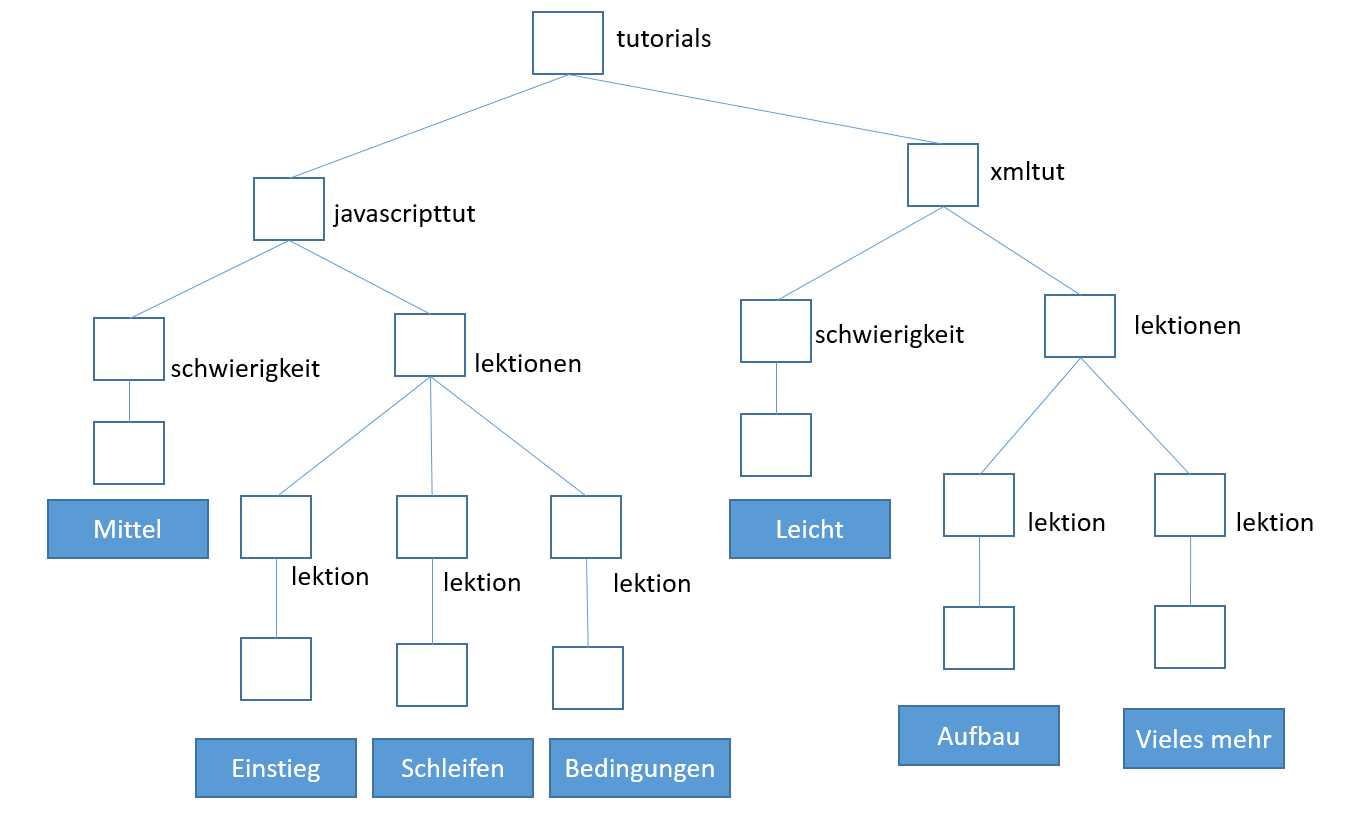
Wie man sieht, wurden in diesem XML-Baum nicht die Attribute mit aufgenommen. Grundsätzlich sind Attribute auch nicht Teil des XML-Baumes. Allerdings kann man diese dennoch mit aufnehmen, man spricht dann von einem erweiterten XML-Baum. Die Baumstruktur erleichtert übrigens die automatische Verarbeitung des Dokuments, da ein XML-Parser einfach nur die Hierarchie abarbeitet und der Baumstruktur folgt.
Weiter geht’s
Das war es erst einmal zur kleinen Einführung über die Grundlagen von XML. Im nächsten Kapitel erfährt man mehr über Datenmodelle in XML bevor die beiden Datenmodelle DTD und XML Schema genauer vorgestellt werden. Weiter geht es mit dem Kapitel Datenmodelle.
Unter Aufbau von XML im 2. Absatz steht: „Ein Element kann verschiedene Inhalte aufweise“, da fehlt das „n“ bei aufweisen.
Im XML Baum habt Ihr zwar als Element: „Einfach“ geschrieben aber in der Baumgrafik selbst wird als Element: „leicht“ angezeigt? Ist das so richtig (wenn ja warum?) oder ist dies versehentlich geschehen?
Hallo Werner,
vielen Dank für deinen Kommentar. Den Rechtschreibfehler habe ich korrigiert.
Auch bei deiner Anmerkung zum Baum hast du völlig recht. Das Attribut muss entweder beides mal „Einfach“ oder beides mal „Leicht“ sein. Da bin ich wohl etwas durcheinander gekommen. Da ich die Grafik des Baums nicht so einfach ändern kann, habe ich nun die XML-Darstellung angepasst. Auch hier herzlichen Dank für den Hinweis!
Beste Grüße
Christian